Tutorial: Open-Domain QA on Tables
Last Updated: December 15, 2022
This tutorial shows you how to perform question-answering on tables using the EmbeddingRetriever or BM25Retriever as retriever node and the TableReader as reader node.
Prepare environment
Colab: Enable the GPU runtime
Make sure you enable the GPU runtime to experience decent speed in this tutorial. Runtime -> Change Runtime type -> Hardware accelerator -> GPU
You can double check whether the GPU runtime is enabled with the following command:
%%bash
nvidia-smi
To start, install the latest release of Haystack with pip:
%%bash
pip install --upgrade pip
pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]
# Install pygraphviz for visualization of Pipelines
apt install libgraphviz-dev
pip install pygraphviz
Logging
We configure how logging messages should be displayed and which log level should be used before importing Haystack. Example log message: INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
import logging
logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
logging.getLogger("haystack").setLevel(logging.INFO)
Start an Elasticsearch server
You can start Elasticsearch on your local machine instance using Docker. If Docker is not readily available in your environment (eg., in Colab notebooks), then you can manually download and execute Elasticsearch from source.
# Recommended: Start Elasticsearch using Docker via the Haystack utility function
from haystack.utils import launch_es
launch_es()
Start an Elasticsearch server in Colab
If Docker is not readily available in your environment (e.g. in Colab notebooks), then you can manually download and execute Elasticsearch from source.
%%bash
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.2-linux-x86_64.tar.gz -q
tar -xzf elasticsearch-7.9.2-linux-x86_64.tar.gz
chown -R daemon:daemon elasticsearch-7.9.2
%%bash --bg
sudo -u daemon -- elasticsearch-7.9.2/bin/elasticsearch
# Connect to Elasticsearch
import os
import time
from haystack.document_stores import ElasticsearchDocumentStore
# Wait 30 seconds only to be sure Elasticsearch is ready before continuing
time.sleep(30)
# Get the host where Elasticsearch is running, default to localhost
host = os.environ.get("ELASTICSEARCH_HOST", "localhost")
document_index = "document"
document_store = ElasticsearchDocumentStore(host=host, username="", password="", index=document_index)
Add Tables to DocumentStore
To quickly demonstrate the capabilities of the EmbeddingRetriever and the TableReader we use a subset of 1000 tables and text documents from a dataset we have published in
this paper.
Just as text passages, tables are represented as Document objects in Haystack. The content field, though, is a pandas DataFrame instead of a string.
# Let's first fetch some tables that we want to query
# Here: 1000 tables from OTT-QA
from haystack.utils import fetch_archive_from_http
doc_dir = "data/tutorial15"
s3_url = "https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-qa/datasets/documents/table_text_dataset.zip"
fetch_archive_from_http(url=s3_url, output_dir=doc_dir)
# Add the tables to the DocumentStore
import json
from haystack import Document
import pandas as pd
def read_tables(filename):
processed_tables = []
with open(filename) as tables:
tables = json.load(tables)
for key, table in tables.items():
current_columns = table["header"]
current_rows = table["data"]
current_df = pd.DataFrame(columns=current_columns, data=current_rows)
document = Document(content=current_df, content_type="table", id=key)
processed_tables.append(document)
return processed_tables
tables = read_tables(f"{doc_dir}/tables.json")
document_store.write_documents(tables, index=document_index)
# Showing content field and meta field of one of the Documents of content_type 'table'
print(tables[0].content)
print(tables[0].meta)
Initialize Retriever, Reader & Pipeline
Retriever
Retrievers help narrowing down the scope for the Reader to a subset of tables where a given question could be answered. They use some simple but fast algorithm.
Here: We specify an embedding model that is finetuned so it can also generate embeddings for tables (instead of just text).
Alternatives:
BM25Retrieverthat uses BM25 algorithm
from haystack.nodes.retriever import EmbeddingRetriever
retriever = EmbeddingRetriever(document_store=document_store, embedding_model="deepset/all-mpnet-base-v2-table")
# Add table embeddings to the tables in DocumentStore
document_store.update_embeddings(retriever=retriever)
## Alternative: BM25Retriever
# from haystack.nodes.retriever import BM25Retriever
# retriever = BM25Retriever(document_store=document_store)
# Try the Retriever
retrieved_tables = retriever.retrieve("Who won the Super Bowl?", top_k=5)
# Get highest scored table
print(retrieved_tables[0].content)
Reader
The TableReader is based on TaPas, a transformer-based language model capable of grasping the two-dimensional structure of a table. It scans the tables returned by the retriever and extracts the anser. The available TableReader models can be found
here.
Notice: The TableReader will return an answer for each table, even if the query cannot be answered by the table. Furthermore, the confidence scores are not useful as of now, given that they will always be very high (i.e. 1 or close to 1).
from haystack.nodes import TableReader
reader = TableReader(model_name_or_path="google/tapas-base-finetuned-wtq", max_seq_len=512)
# Try the TableReader on one Table
table_doc = document_store.get_document_by_id("36964e90-3735-4ba1-8e6a-bec236e88bb2")
print(table_doc.content)
from haystack.utils import print_answers
prediction = reader.predict(query="Who played Gregory House in the series House?", documents=[table_doc])
print_answers(prediction, details="all")
The offsets in the offsets_in_document and offsets_in_context field indicate the table cells that the model predicts to be part of the answer. They need to be interpreted on the linearized table, i.e., a flat list containing all of the table cells.
print(f"Predicted answer: {prediction['answers'][0].answer}")
print(f"Meta field: {prediction['answers'][0].meta}")
Pipeline
The Retriever and the Reader can be sticked together to a pipeline in order to first retrieve relevant tables and then extract the answer.
Notice: Given that the TableReader does not provide useful confidence scores and returns an answer for each of the tables, the sorting of the answers might be not helpful.
# Initialize pipeline
from haystack import Pipeline
table_qa_pipeline = Pipeline()
table_qa_pipeline.add_node(component=retriever, name="EmbeddingRetriever", inputs=["Query"])
table_qa_pipeline.add_node(component=reader, name="TableReader", inputs=["EmbeddingRetriever"])
prediction = table_qa_pipeline.run("When was Guilty Gear Xrd : Sign released?", params={"top_k": 30})
print_answers(prediction, details="minimum")
# Add 500 text passages to our document store.
def read_texts(filename):
processed_passages = []
with open(filename) as passages:
passages = json.load(passages)
for key, content in passages.items():
document = Document(content=content, content_type="text", id=key)
processed_passages.append(document)
return processed_passages
passages = read_texts(f"{doc_dir}/texts.json")
document_store.write_documents(passages, index=document_index)
document_store.update_embeddings(retriever=retriever, update_existing_embeddings=False)
Pipeline for QA on Combination of Text and Tables
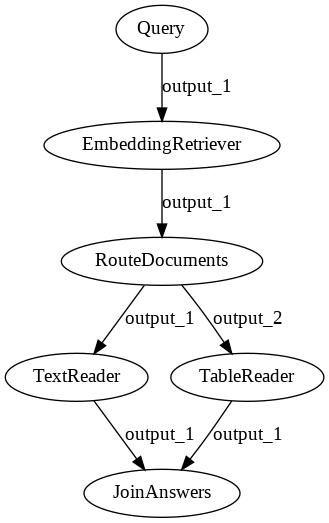
We are using one node for retrieving both texts and tables, the EmbeddingRetriever. In order to do question-answering on the Documents coming from the EmbeddingRetriever, we need to route Documents of type "text" to a FARMReader (or alternatively TransformersReader) and Documents of type "table" to a TableReader.
To achieve this, we make use of two additional nodes:
RouteDocuments: Splits the List of Documents retrieved by theEmbeddingRetrieverinto two lists containing only Documents of type"text"or"table", respectively.JoinAnswers: Takes Answers coming from two different Readers (in this caseFARMReaderandTableReader) and joins them to a single list of Answers.
from haystack.nodes import FARMReader, RouteDocuments, JoinAnswers
text_reader = FARMReader("deepset/roberta-base-squad2")
# In order to get meaningful scores from the TableReader, use "deepset/tapas-large-nq-hn-reader" or
# "deepset/tapas-large-nq-reader" as TableReader models. The disadvantage of these models is, however,
# that they are not capable of doing aggregations over multiple table cells.
table_reader = TableReader("deepset/tapas-large-nq-hn-reader")
route_documents = RouteDocuments()
join_answers = JoinAnswers()
text_table_qa_pipeline = Pipeline()
text_table_qa_pipeline.add_node(component=retriever, name="EmbeddingRetriever", inputs=["Query"])
text_table_qa_pipeline.add_node(component=route_documents, name="RouteDocuments", inputs=["EmbeddingRetriever"])
text_table_qa_pipeline.add_node(component=text_reader, name="TextReader", inputs=["RouteDocuments.output_1"])
text_table_qa_pipeline.add_node(component=table_reader, name="TableReader", inputs=["RouteDocuments.output_2"])
text_table_qa_pipeline.add_node(component=join_answers, name="JoinAnswers", inputs=["TextReader", "TableReader"])
# Remove the following comment to generate the structure of the combined Table an Text QA pipeline.
# text_table_qa_pipeline.draw("pipeline.png")
# Example query whose answer resides in a text passage
predictions = text_table_qa_pipeline.run(query="Who was Thomas Alva Edison?")
# We can see both text passages and tables as contexts of the predicted answers.
print_answers(predictions, details="minimum")
# Example query whose answer resides in a table
predictions = text_table_qa_pipeline.run(query="Which country does the film Macaroni come from?")
# We can see both text passages and tables as contexts of the predicted answers.
print_answers(predictions, details="minimum")
Evaluation
To evaluate our pipeline, we can use haystack’s evaluation feature. We just need to convert our labels into MultiLabel objects and the eval method will do the rest.
from haystack import Label, MultiLabel, Answer
def read_labels(filename, tables):
processed_labels = []
with open(filename) as labels:
labels = json.load(labels)
for table in tables:
if table.id not in labels:
continue
label = labels[table.id]
label = Label(
query=label["query"],
document=table,
is_correct_answer=True,
is_correct_document=True,
answer=Answer(answer=label["answer"]),
origin="gold-label",
)
processed_labels.append(MultiLabel(labels=[label]))
return processed_labels
table_labels = read_labels(f"{doc_dir}/labels.json", tables)
passage_labels = read_labels(f"{doc_dir}/labels.json", passages)
eval_results = text_table_qa_pipeline.eval(table_labels + passage_labels, params={"top_k": 10})
# Calculating and printing the evaluation metrics
print(eval_results.calculate_metrics())
Adding tables from PDFs
It can sometimes be hard to provide your data in form of a pandas DataFrame. For this case, we provide the ParsrConverter wrapper that can help you to convert, for example, a PDF file into a document that you can index.
Attention: parsr needs a docker environment for execution, but Colab doesn’t support docker.
If you have a local docker environment, you can uncomment and run the following cells.
# import time
# !docker run -d -p 3001:3001 axarev/parsr
# time.sleep(30)
# !wget https://www.w3.org/WAI/WCAG21/working-examples/pdf-table/table.pdf
# from haystack.nodes import ParsrConverter
# converter = ParsrConverter()
# docs = converter.convert("table.pdf")
# tables = [doc for doc in docs if doc.content_type == "table"]
# print(tables)
About us
This Haystack notebook was made with love by deepset in Berlin, Germany
We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our other work:
Get in touch: Twitter | LinkedIn | Discord | GitHub Discussions | Website
By the way: we’re hiring!